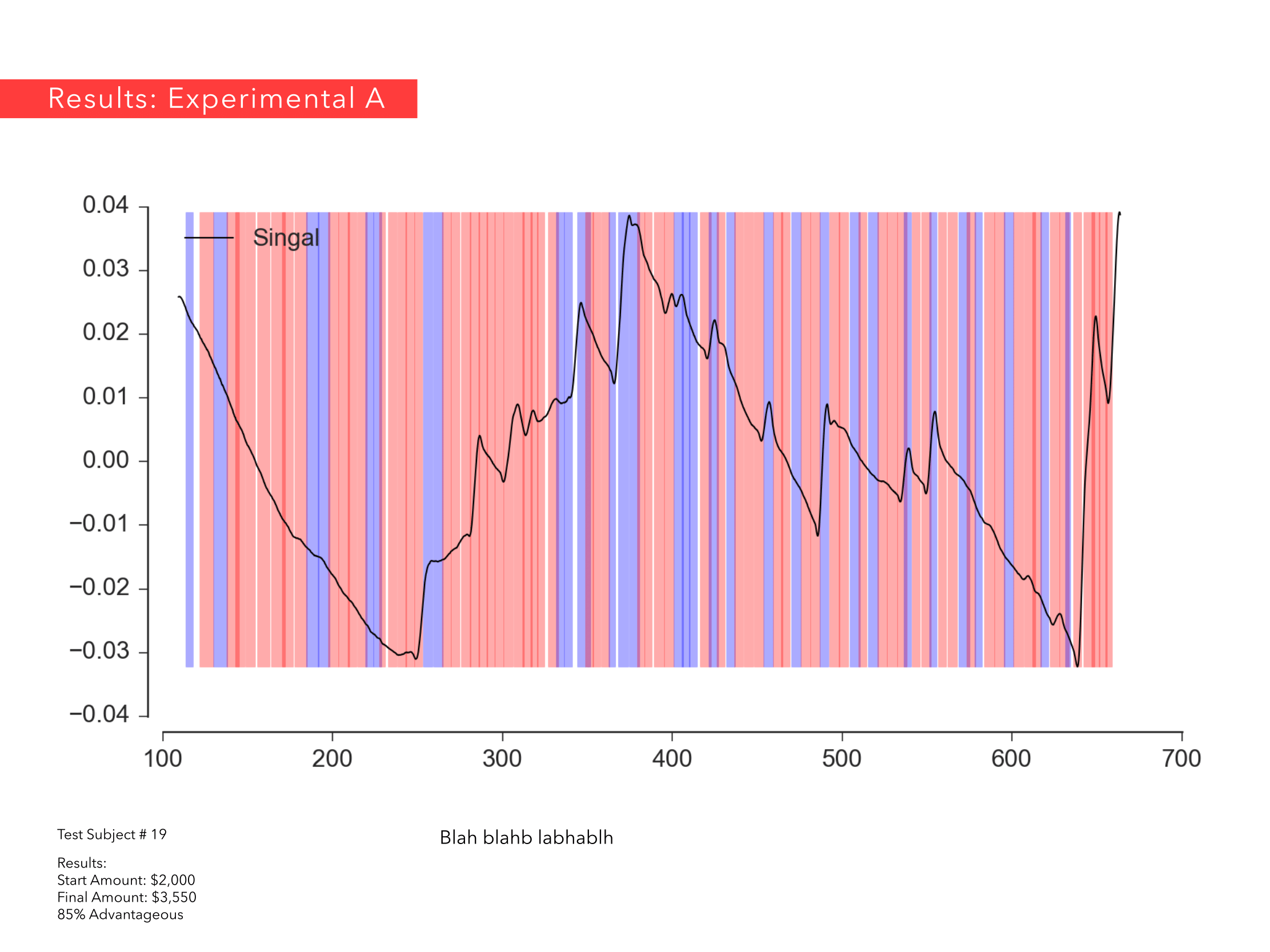
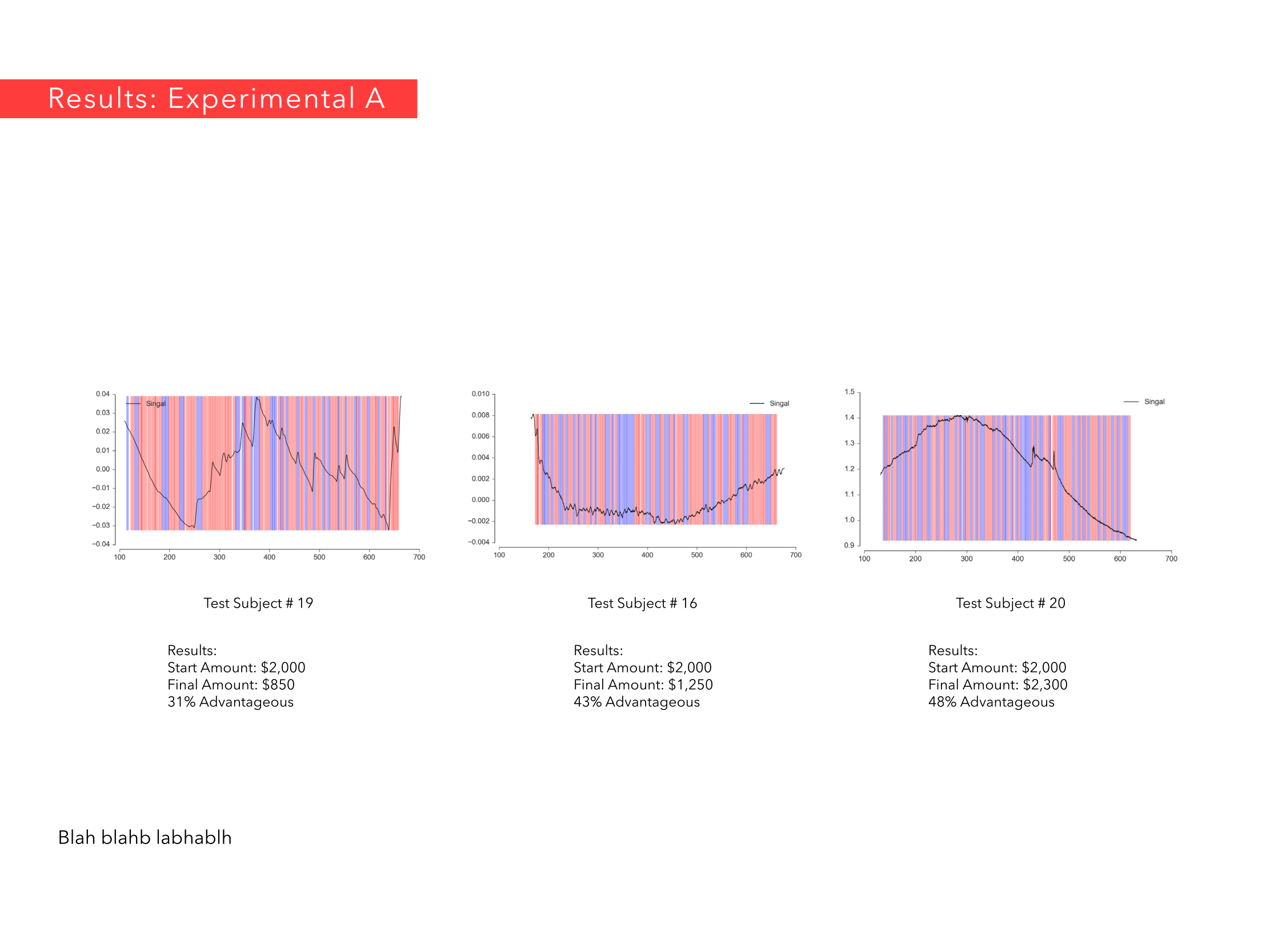
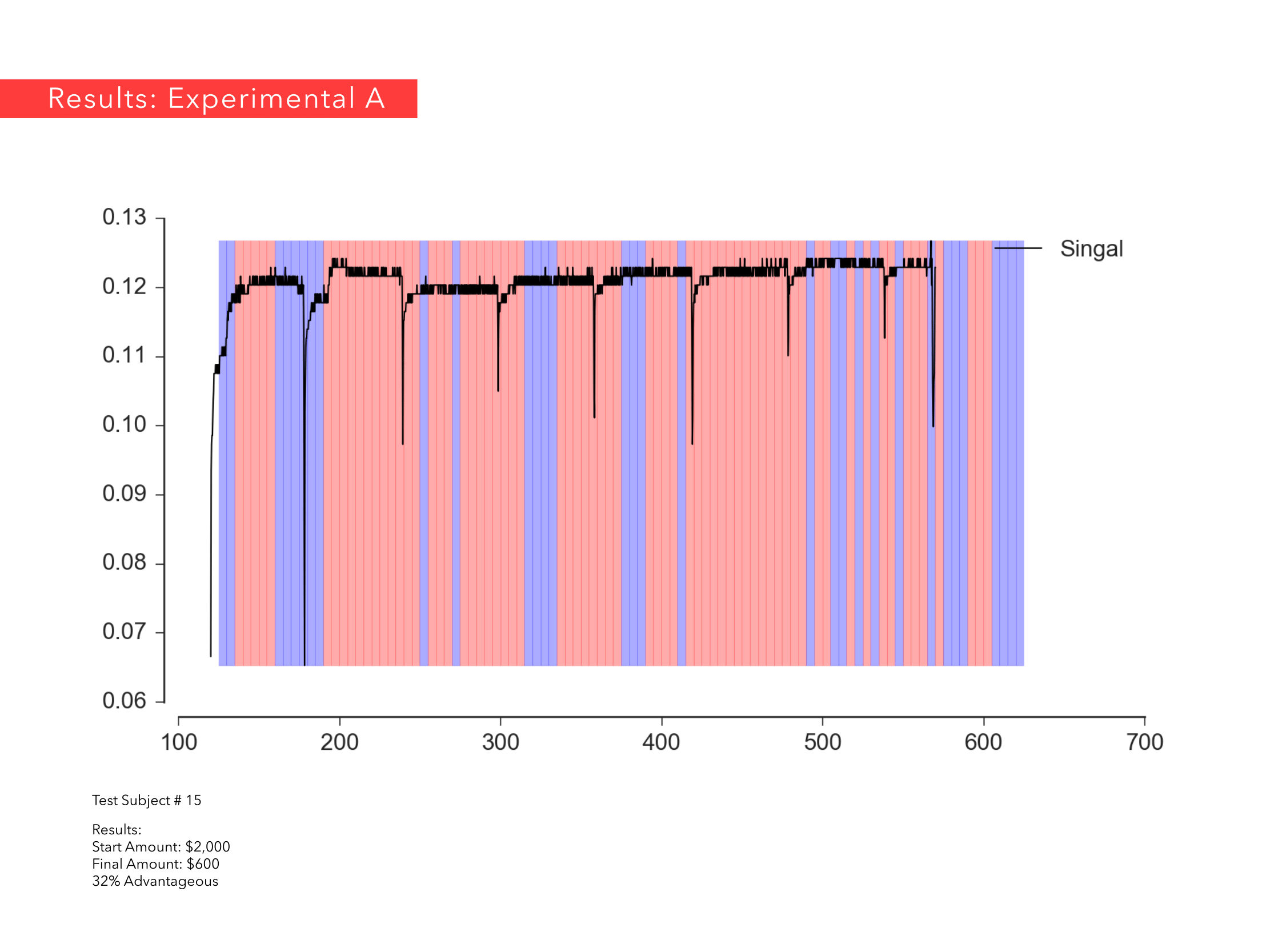
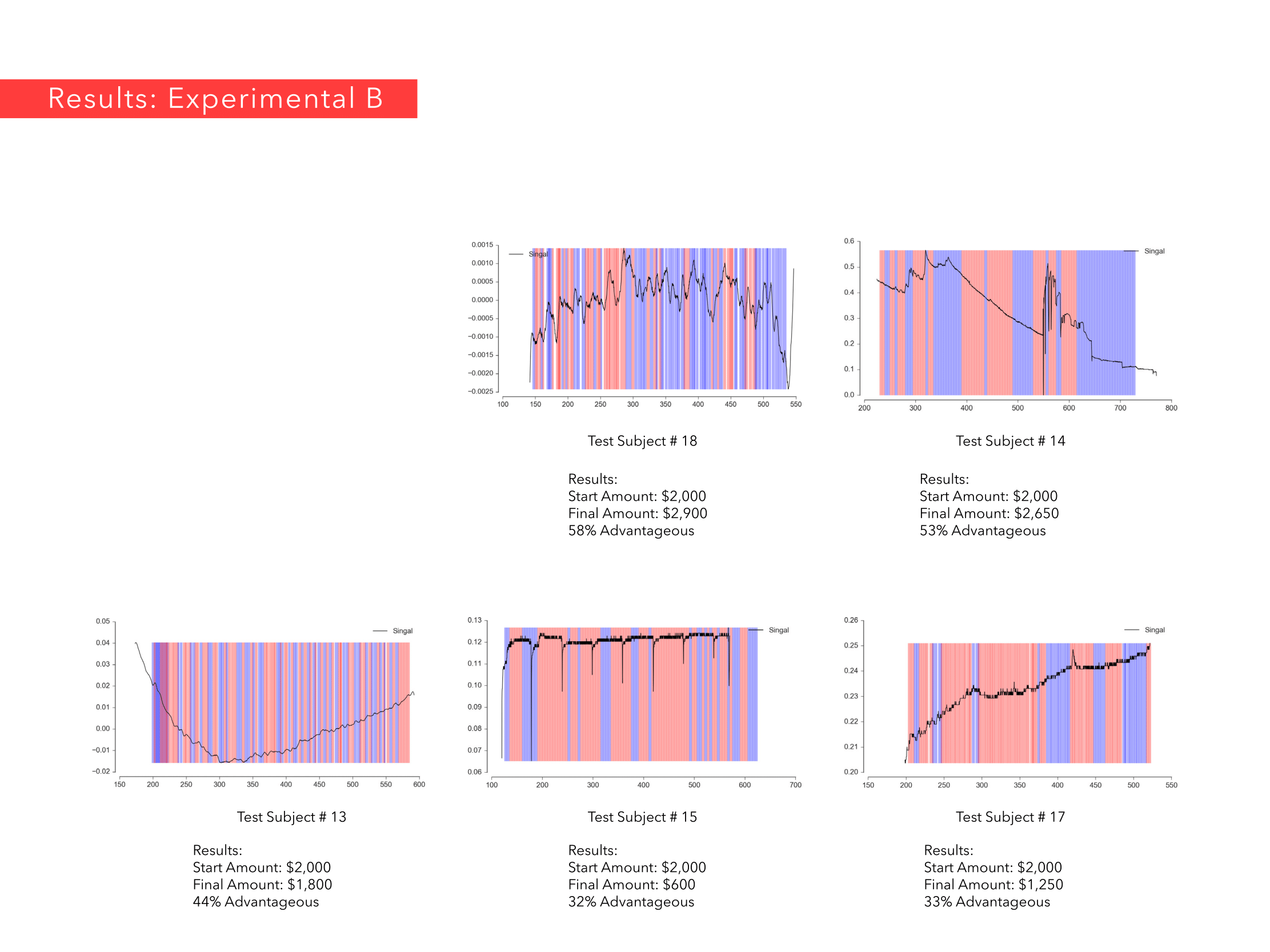
Ricardo Jnani Gonzalez & Cagri Hakan Zaman
Abstract.
Memory Architect (MA) is a project about Space and Memory. We created a Virtual Reality (VR) framework that allows a user to compose past experiences, organize their memories, and create new connections between them in a spatially immersive virtual environment. In the Virtual Memory Palace, through the use of our MA App, the person is able embed images, videos, document files, sound recordings, and even real 3D spaces into digital models they create. Then, they are able to organize these spaces as a way to alter the memory’s context. In other words, they they can place two very different memories together as way to gain a different perspective on the scenarios; they can increase or decrease the size of certain memories; they can combine two separate events into one memory, or break one into its separate aspects. Through the use of Google’s Project Tango and Unity, these models are turned into a VR space in which the user is able to both physically, and virtually walk round in. The user, by moving, kneeling, walking, etc., is able to navigate their virtual architecture holding their composed memories.
Background & Vision
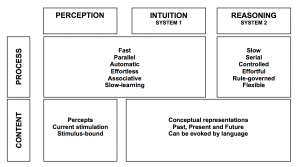
In this project we propose that remembering is a form of creation, rather than an information retrieval. In this active, embodied process, space plays a crucial role. We do not only reassemble past experiences in a given context, but we do it within a particular spatial setting. In this section, we provide evidences about our embodied-memory approach from the lens of neuroscience and social sciences.
Neuroscientific Account
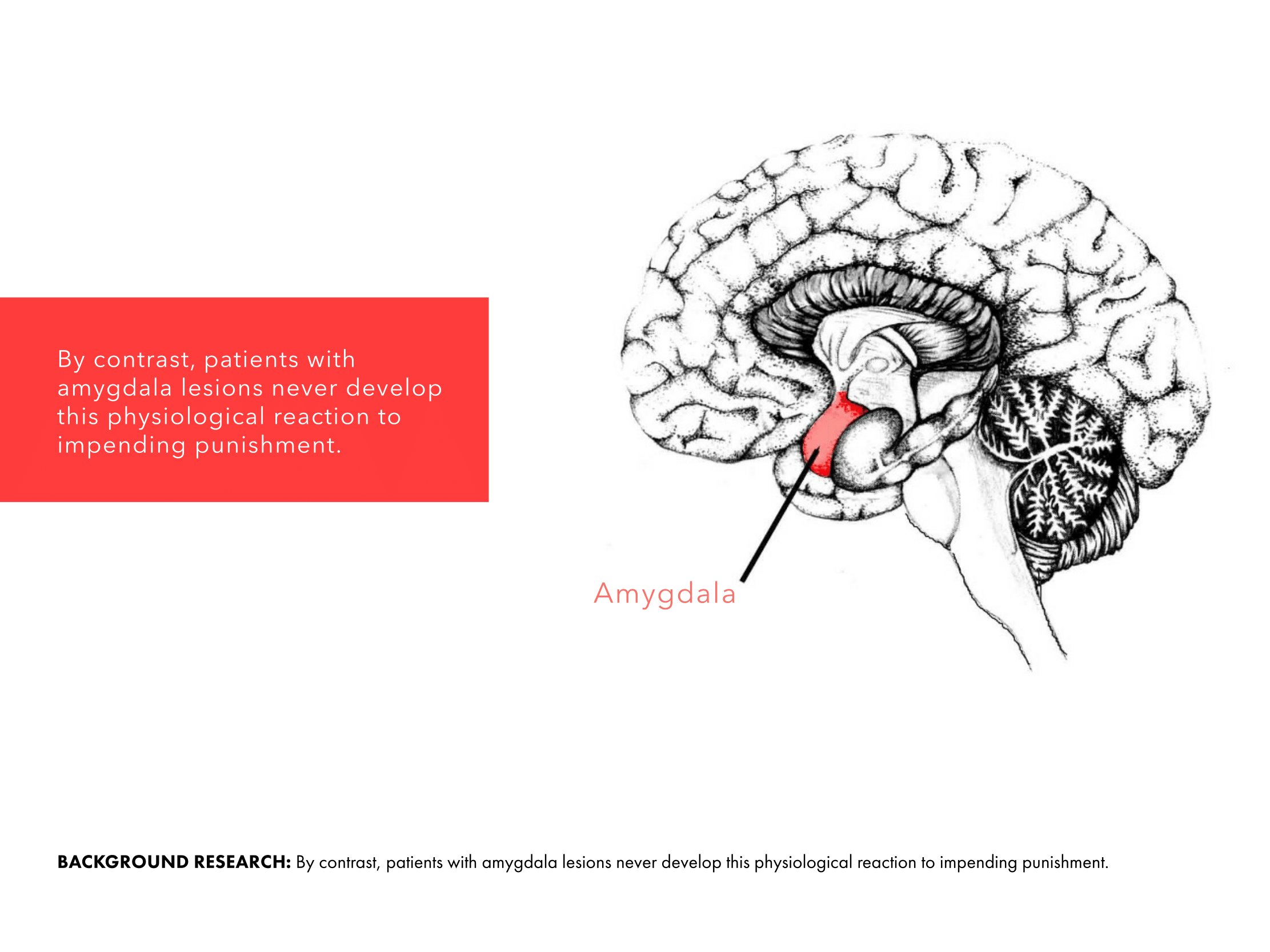
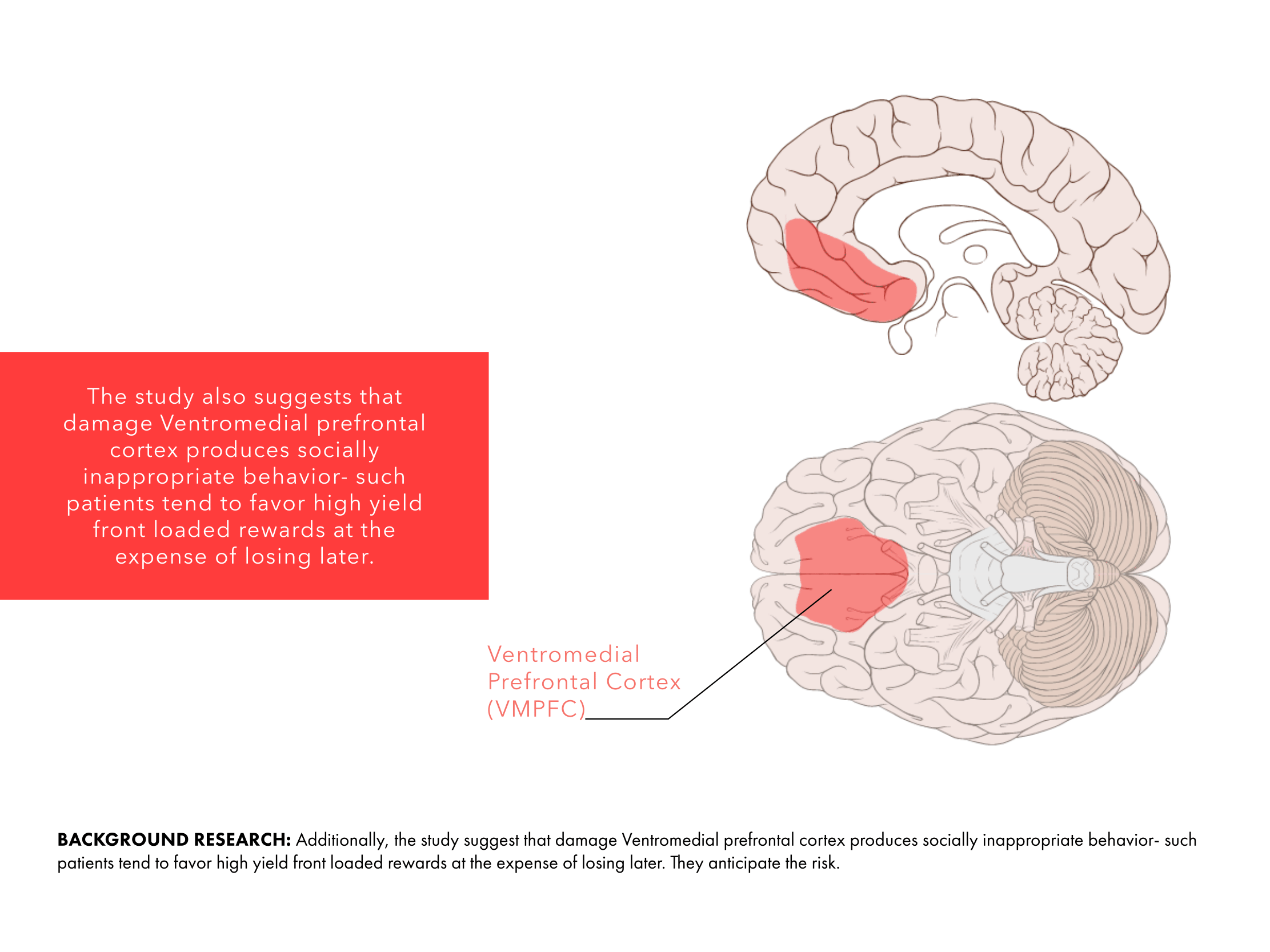
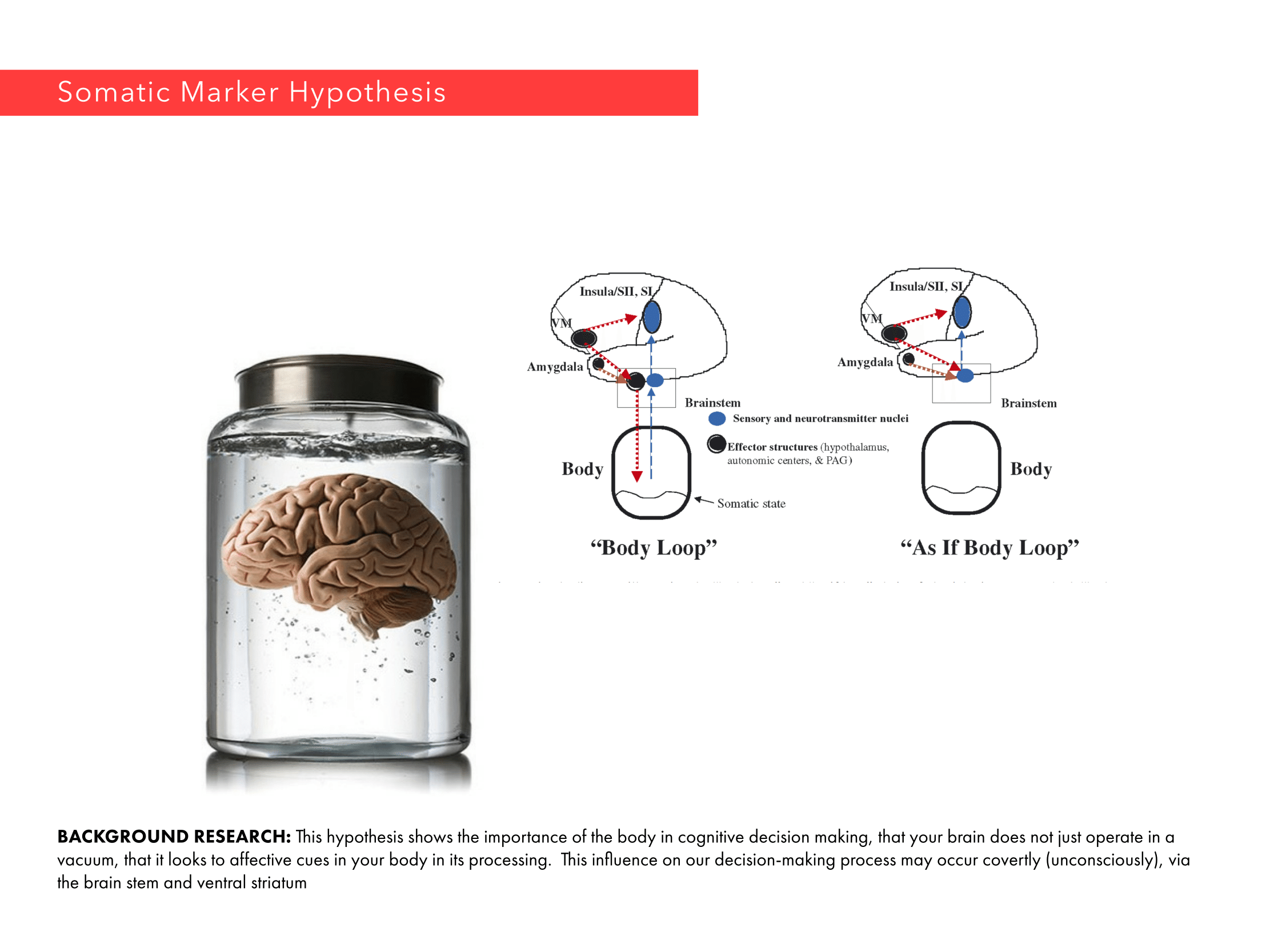
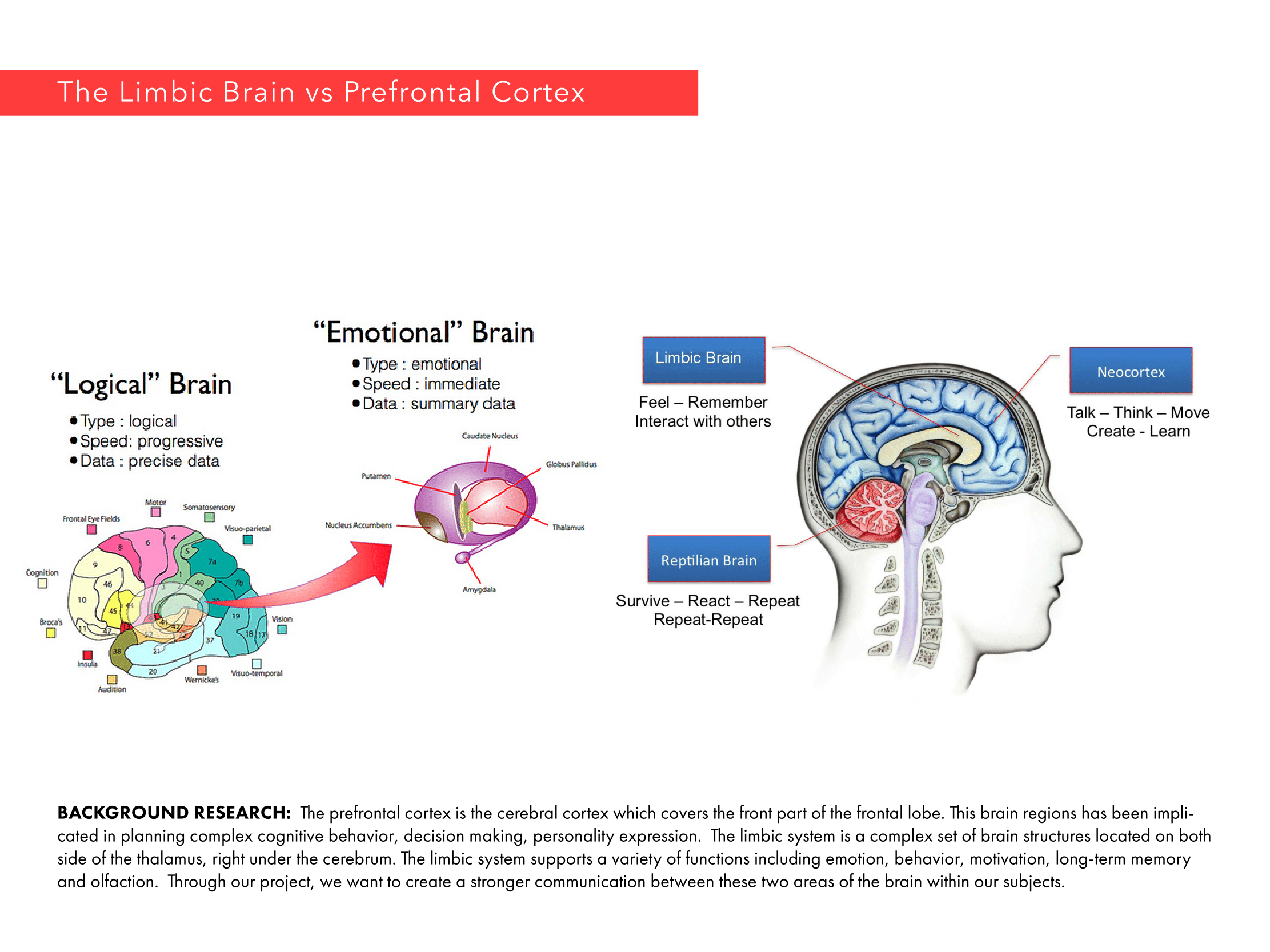
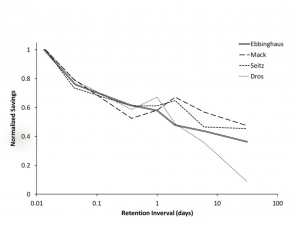
Our brains spend a tremendous effort to resolve space, integrate the sensory information into practical information so that it can plan where to move, where to sit; remember a particular place so it can navigate back when it is necessary. Basic characteristics of spatial perception have been discovered through studies on rat hippocampus. (O’Keefe & Nadel, 1978; Ranck, 1973; Emery, Wilson & Chen, 2012). Hippocampus is a main processing unit in the brain where short term memories are encoded in long term memories. However, the majority of cell formations in hippocampus also play a central role spatial perception and navigation, namely the “place cells”. Different firing patterns in place cell region allow the animal to represents its location relative to the objects in the environment. While place cells respond to different visual cues in the environment, they also integrate proprioceptive information as to direction and velocity, as well as the sensory information other than visual ones such as sound or odor. They exhibit firing patterns regardless of the sensory medium as the firing patterns have been discovered in deaf and blind rats. (Hill & Best, 1981;Save, Cressant, Thinus-Blanc, & Poucet, 1998). Spike pattern of a particular place cell is correlated to the change in size, orientation and shape of the environment (O’Keefe, 1998). In addition to evidently location selective place cells, there are other neural compositions in brain such as grid cells, head direction cells and boundary cells, which as a whole provide a reliable information about the environment. PPA in human brain is selective to environmental structures, which would be integrating high and low level features for detection and recognition of visual scenes.
Space, Body and Action
In order to understand the dynamic interaction between action and space one should consider the human body as the natural locus of the experience. The geographer Yi-Fu Tuan states “Upright, man is ready to act. Space opens out before him and is immediately differentiable into front-back and right–left axes in conformity with the structure of his body” (2001). Spatial experience is imposed directly by the structure of the body as well as its ability to respond within physical constraints. Equipped with sensory-motor apparatus, the human body drives the experience by actively engaging with the environment. The French social scientist Michel de Certeau proposes that space can only be experienced through this active participation “when one takes into consideration vectors of direction, velocities, and time variables”.

Memory Architect: Remembering as Reconsideration
In this project we explore the possibilities of using the immediate interaction between memory and space, and allow users to creatively interact with their own memories. Memory Architect is a place for creative remembering which would allow users to augment their memories, trigger their creative thinking as well as share their subjective points of views and memories with each other.
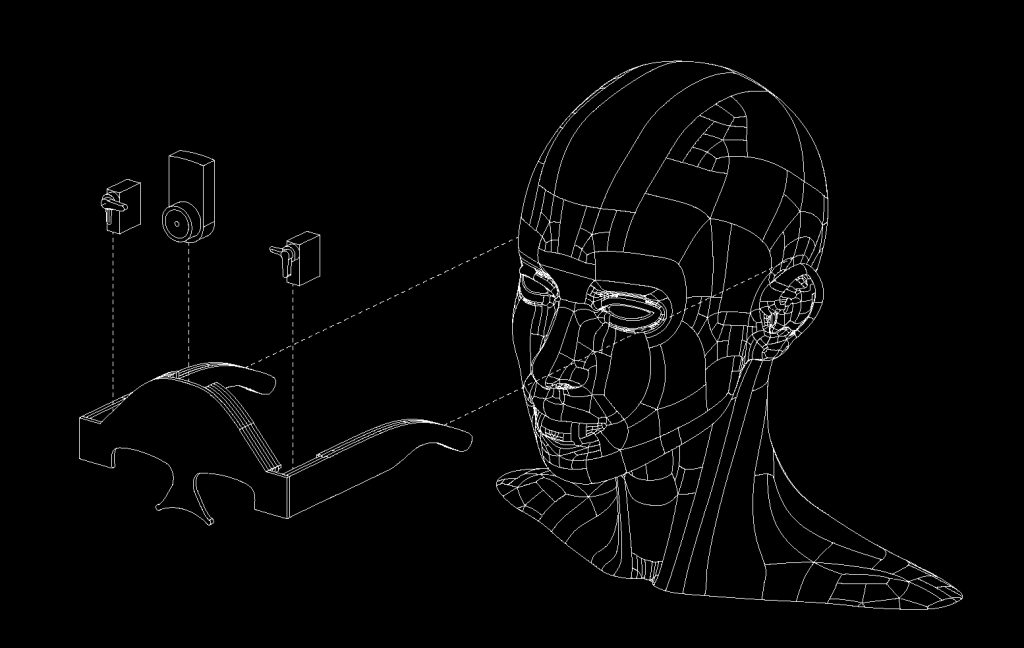
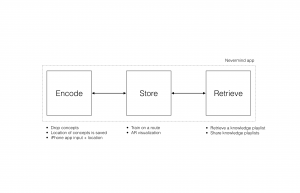
Our system consists of three stages: Build, Log and Explore. Through a mobile app, users can build memory cells –basic units of memory containers– and attach their memories inside. The mobile app allows users to create, edit and merge different memory cells. Users may upload any type of media –from texts and images to three dimensional models to their virtual memory palace. Once they are uploaded, the system is ready to be explored. We use Google Tango for freely navigate in VR without being limited to certain area. We believe, it is particularly important to let users to engage with the virtual content with their bodies, by moving and exploring the space naturally.
The Mobile Interface
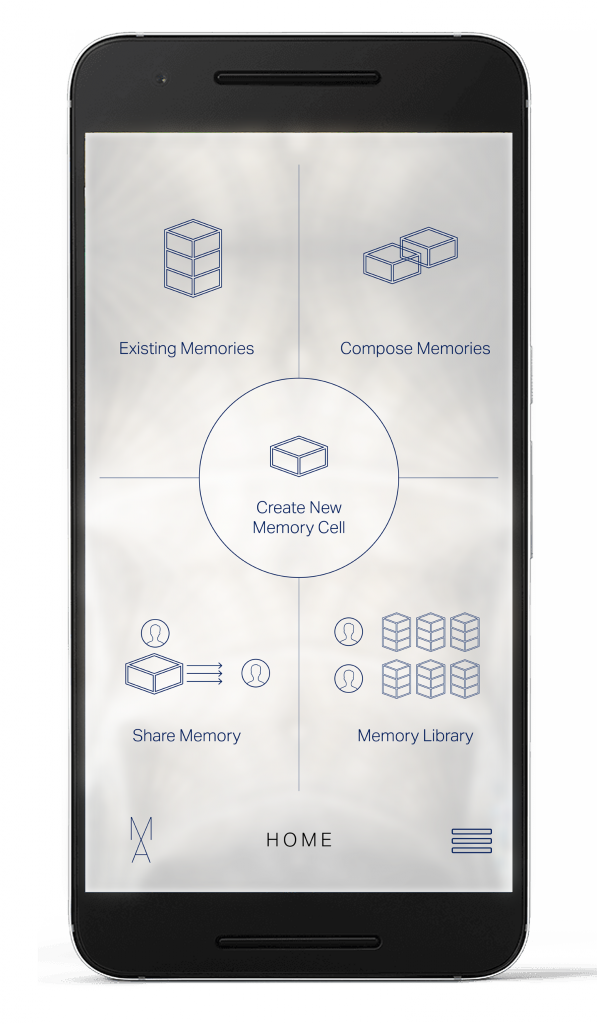
Here we see the Home screen of MA. First, the user can choose to Create a New Memory Cell in which to place some form of media that captures a memory. If they’ve already created memory cells, they can go back to view or edit what lives in each of them. Similarly, the app would allow them to organize previous cells, as a way to compose, recreate, or shake up, their stored memories. We envision that as the user creates virtual spaces filled with their experiences, they may want to share some of them with others. This feature would allow you to send a particular space you’ve created and filled with moments to others. Similarly, the user could choose to publish a particular memory for everyone in the network to have access to. Whether it’s a personal memory space they wish everyone to see, or a space of learning that captures the many aspects of a topic, this Library of Shared Memories would allow selected access to a larger world of composed experiences, and curated memories. These five functions of the system will be discussed in more detail in the following sections.

Build
We envision a very simple interface of creating and composing virtual spaces. Through a 3D modeling system embedded in the app, the person would have access to a series of basic 3D geometries and architecture typologies. In other words, they could choose from a series of simple square rooms, domes, vaulted hallways, tunnels, etc. They could choose any one of them, and combine several to create their own virtual architecture. The user would also have basic tools like move, scale, rotate. These features would enrich their ability to organize their memories, tweak the hierarchy of their experiences, and curate lived scenarios.

Log
Once a person created a cell, or a series of cells, he/she could insert memories in different ways. Whether it’s through simply taking a snapshot of an event, recording a video or voice, or simply downloading a document file, the app would allow the person to upload a range of media into your own virtual memory palace. The user could choose to create an entire space for a single event, or embed snippets into 3D objects inside the room. We envision the possibility of 3D scanning real spaces into the virtual environment. Users can imagine capturing a pavilion you visited in a vacation, placing it in their virtual memory palace, and merging it with the unalike scenario of their workspace as a way to gain inspiration, prompt bisociation, and induce creativity.


Explore
MA also allows you to store memories in objects arranged throughout the spaces you create. As the user walks through their memory palace, they are be able to insert media of memories into a series of reflective spheres. This is yet another way mixing different types of memories. You can, for example, create a space for a class you’re taking. Throughout the space, there could be images, videos of classes, reference reading files etc., all along the wall. Then, you can add spheres of memories that aren’t directly of the class, but rather relate to the class. These 3D objects in the virtual palace, would be a an additional layer to organizing, composing, and re-creating memories.

Like the virtual spaces, the object itself may have any type of media embedded into it. The spheres however, instead of continuously displaying the memory media, could be triggered into revealing the memory only when you approach it. In this manner, the spheres serve as a simple method of augmenting the virtual space. Through reflecting scenarios that are not necessarily of the space they are placed in, they enhance the experience of one memory, with the insertion of another. The reflectivity of its material, creates a type of memory montage; where multiple scenarios are overlayed over one another.
Organizational Schemas
The organizational layouts of a memory palace are near infinite; you could arrange it almost anyway you want. However, beside giving the user full control over the composition of their memories, the system would have a series of elementary organizational strategies. Location Based for example; you can have the system arrange spaces so that every scenario that happens in a particular place stays within the confines of a given room. That way, the user can go to that space, and speed backwards and forwards in time and view the many stored events of that one place. This would be a very simple way of one type of filtering; keeping work at work, and home at home for example. You could then enhance their separation, so that as you navigate in a memory space of “home”, you will not have any visual access to events from the workplace.
Another simple organizational method, would be to arrange memories through activity. Here again, the user could being to compose the different type of activities, and playing with their proximity. A space of reading and studying for example, could be interestingly enriched by having a portal to the memory of your first picnic in Paris. The user would be able to walk through a dome all of their travels; a valley of all of their hikes; an oculus of their favorite skies.
Prototype
We have developed a prototype in Unity Game Engine for Google Tango, where the app downloads the contents of a memory palace from the server and places them inside a memory cell we designed. The prototype virtual palace can be explored using the Tango and VR goggles.
Future Work
We envision utilizing space as an interface. Through being able to physically walk in a virtual space, motion, pace, volume, material, mass, and flow become tools of engaging the digital world. Without the typical restrain of the physical world, the virtual palace could warp in ways that would allow the user to see spaces beyond where they stand. This method would give them access to see themselves and the memory they are walking through in relation to the overall palace. This method of warping effectively redefines space of memory.
As the person develops their memory palace, they could begin to shape and model it after the real world by capturing 3D spatial scans. This build up over time is accelerated and enhanced through the sharing feature. Eventually the user could have a virtual duplicate of their home, school, town, etc., in which they compose and montage events and moments they want to remember of that particular place.

References
Place Cells and Memory
[1]Park, S.Brady, T.F.Greene, M.R., Oliva, A. 2011.Disentangling scene content from its spatial
boundary: Complementary roles for the parahippocampal place area and lateral occipital complex
in representing real-world scenes Journal of Neuroscience, 31(4), 1333-1340.
[2] Oliva, A., Torralba, A. 2001. Modeling the Shape of the Scene: a Holistic Representation of the
Spatial Envelope. International Journal in Computer Vision, 42, 145-175
[3] Oliva, A. Torralba, A.2006.Building the Gist of a Scene: The Role of Global Image Features in
Recognition. Progress in Brain Research: Visual perception,
[4] O’Keefe, J. and Nadel, L. 1978. The Hippocampus as a Cognitive Map. Oxford: Oxford University.
[5] O’Keefe J Burgess N Donnett J G Jeery K J Maguire E A .1998 Place cells, navigational
accuracy, and the human hippocampus Philos Trans R Soc Lond B Biol Sci. 1998 Aug 29;
353(1373): 1333{1340.
[6] Ranck JB., Jr. 1973.Studies on single neurons in dorsal hippocampal formation and septum in
unrestrained rats. I. Behavioral correlates and ring repertoires. Exp Neurol.41:461{531.
[7] Chen, Z, Kloosterman, F, Brown E N, Wilson, M A,2012. Uncovering spatial topology represented by rat hippocampal population neuronal codes Journal of Computational Neuroscience,
October 2012, Volume 33, Issue 2, pp 227-255
Memory & Space
Foer, Joshua. 2012. Moonwalking with Einstein: The Art and Science of Remembering Everything. London: Penguin Books.
Yates, Frances Amelia. 2002. The Art of Memory. Nachdr. Chicago, Ill.: Univ. of Chicago Press.
Bachelard, Gaston. The Poetics of Space. Boston: Beacon Press, 1969. Print.
Pallasmaa, Juhani. The Eyes of the Skin: Architecture and the Senses. Chichester: Wiley-Academy, 2005. Print.
Abbott, Edwin A. Flatland: A Romance of Many Dimensions. Champaign, Ill: Project Gutenberg, 1990. Internet resource.
Bergson, Henri, Nancy M. Paul, and William S. Palmer. Matter and Memory. London: G. Allen & Co, 1912. Print.
Ai, Weiwei, Anthony Pins, and Weiwei Ai. Ai Weiwei: Spatial Matters : Art Architecture and Activism. , 2014. Print.
Grynsztejn, Madeleine, Elíasson Ólafur, Daniel Birnbaum, and Michael Speaks. Olafur Eliasson. London: Phaidon Press, 2002. Print.
Olafur, Eliasson, and Günther Vogt. Olafur Eliasson – the Mediated Motion. Köln: W. König, 2001. Print.
Beccaria, Marcella, Elíasson Ólafur, and Simon Turner. Olafur Eliasson: Oe. , 2013. Print.
Pallasmaa, Juhani, and Peter Zumthor. Sfeer Bouwen =: Building Atmosphere. Rotterdam: Nai010 Pub, 2013. Print.
Jones, Caroline A, and Bill Arning. Sensorium: Embodied Experience, Technology, and Contemporary Art. Cambridge, Mass: MIT Press, 2006. Print.
Rosenau, Helen, Etienne L. Boullee, and Etienne L. Boullee. Boullee & Visionary Architecture: Including Boullee’s Architecture, Essay on Art. London: Academy Editions, 1976. Print.
Lemagny, Jean-Claude. Visionary Architects: Boullée, Ledoux, Lequeu. Houston, Tex.: Printed by Gulf Print. Co., 1968. Print.